

Este podría ser el «número mágico» para la Inteligencia Artificial en Europa, igual ahora no te suena demasiado pero vamos a intentar explicarlo de manera sencilla.
Lo primero de todo, los «FLOPS» hacen referencia a la cantidad de operaciones que un ordenador puede realizar en un segundo; más en concreto operaciones aritméticas con números de punto flotante, Floating Point Operations Per Second.
Acabamos de empezar y ya estamos con palabrotas técnicas, solo un par más. Por cierto, en países de habla hispana lo denominamos «coma flotante» porque utilizamos de forma diferente los separadores de decimales, el concepto es el mismo.
¿Qué precisión de datos necesitamos? En la vida real depende…
- Un arquitecto construyendo un edificio, no notará mucha diferencia entre 20 metros y 20.000001 metros de una pared de tu casa.
- La maniobra de aterrizaje del propulsor Super Heavy de 70 metros de altura, aterrizó con una precisión de 0.005 metros (medio centímetro)
- Un físico midiendo el tamaño de un electrón 0,0000000000000001 metros
Arquímedes (año 212 A.C.) en su obra «El contador de arena» buscaba expresar la cantidad de granos de arena que llenarían el universo. Por aquel entonces exploraba métodos para representar y conceptualizar magnitudes gigantescas. Aunque no utiliza la notación científica moderna, sus ideas sentaron las bases para sistemas de numeración posteriores. Número tan grandes que no nos entran en la cabeza.
En la actualidad, los escenarios de uso son muy diversos aunque la mayoría de ordenadores utilizan el estándar IEEE 754, si queremos utilizar una precisión enorme ¡tenemos que poder guardarla y trabajar con ella! Para entrenar puede utilizarse una precisión FP32 pero para inferencia (generar respuestas a partir del modelo entrenado sobre datos nuevos no conocidos) puede utilizarse FP16 o incluso INT8
A continuación un ejemplo de como almacenar el valor con diferente precisión, en este caso el número 1.234.567.890:

El proceso de transformar los datos de entrenamiento (generalmente texto) en vectores numéricos lo explicaremos otro día (tokenización, indexación, embeddings, transformers…) hoy seguimos con el número mágico.
Si aplicamos la precisión de datos a Inteligencia Artificial dependerá también del contexto, tarea a realizar, modelo a entrenar, inferencia, hardware… Los diferentes Modelos de Lenguaje de Gran Escala (LLM, Large Language Model) como ChatGPT, Grok, Llama, PaLM, Bard, Ernie, Claude, Mistral, Gemini, Bloom, Turin-NLG… no revelan los detalles de su entrenamiento, aunque se lo preguntes…

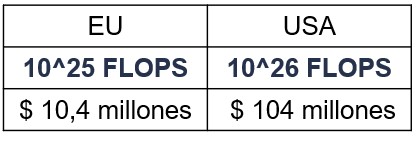
Con todo ello la Unión Europea ha fijado en 10^25 FLOPS el umbral de riesgo sistémico como primer indicador de la capacidad de los modelos, además «puede actualizar este número al alza o a la baja en función de los avances en la medición objetiva de las capacidades de los modelos», «es razonable someter a sus proveedores al conjunto adicional de obligaciones»
En Estados Unidos, Joe Biden fijó en una Orden Ejecutiva el 30 de octubre de 2023 en 10^26 FLOPS, veremos si Donald Trump continua en la misma senda o modifica estas limitaciones regulatorias en 2025, para regular el desarrollo y uso de la IA en el país. Lo que solo parece un número, supone mucho más de lo que pueda parecer.
En el proceso se utilizan tarjetas gráficas (GPU, Graphics Processing Unit) al ser más eficientes para el cálculo con coma flotante, escalabilidad, paralelismo… a la hora de realizar entrenamiento de los modelos que los procesadores (CPU, Central Processing Unit). Las recientes NPU (Neural Processing Unit) que iremos viendo popularizarse en ordenadores, móviles y otros dispositivos durante el próximo año están destinadas a acelerar procesos de inferencia de manera más eficiente (energía y latencia) siendo tecnologías perfectamente complementarias y la que más directamente veremos como usuarios finales de sistemas basados en IA.
Para ser más realistas, el propio Jack Clark (cofundador de Anthropic) realizó una estimación con hardware NVIDIA H100, previsión de errores de cálculo, clúster… para mostrar la diferencia en costes resumida de la comparativa en 2024:
¿Qué empresas compiten en esta liga? Pocas… la más reciente e incipiente xAI utilizó 15.000 NVIDIA H100 para igualar Grok 2 a GPT-4, que posteriormente ampliaron a 100,000 GPUs en una instalación de tan solo 122 días:
¿Entendemos por donde van las regulaciones ahora? Obviamente el apartado de «multas» sobre el volumen de negocios anual seguro que lo detallan muy bien…
¿En que puede afectarme como pequeña empresa en España? Realmente podrás seguir integrando y utilizando como servicio (SaaS) los proveedores de IA que mejor se adapten a tus necesidades de integración, seguridad, precio… pero los sobrecostes que puedan tener las empresas en cuanto a regulaciones adicionales los acabaremos pagando los usuarios finales.
Si tienes más preguntas no dudes en contactar con nosotros.








1 Comment
Comments are closed.